U-net
Unet是2015年发的论文,起初用于医学图像处理,Unet这篇论文提出了如何利用少样本进行深度学习,模型训练效果较优。
模型架构
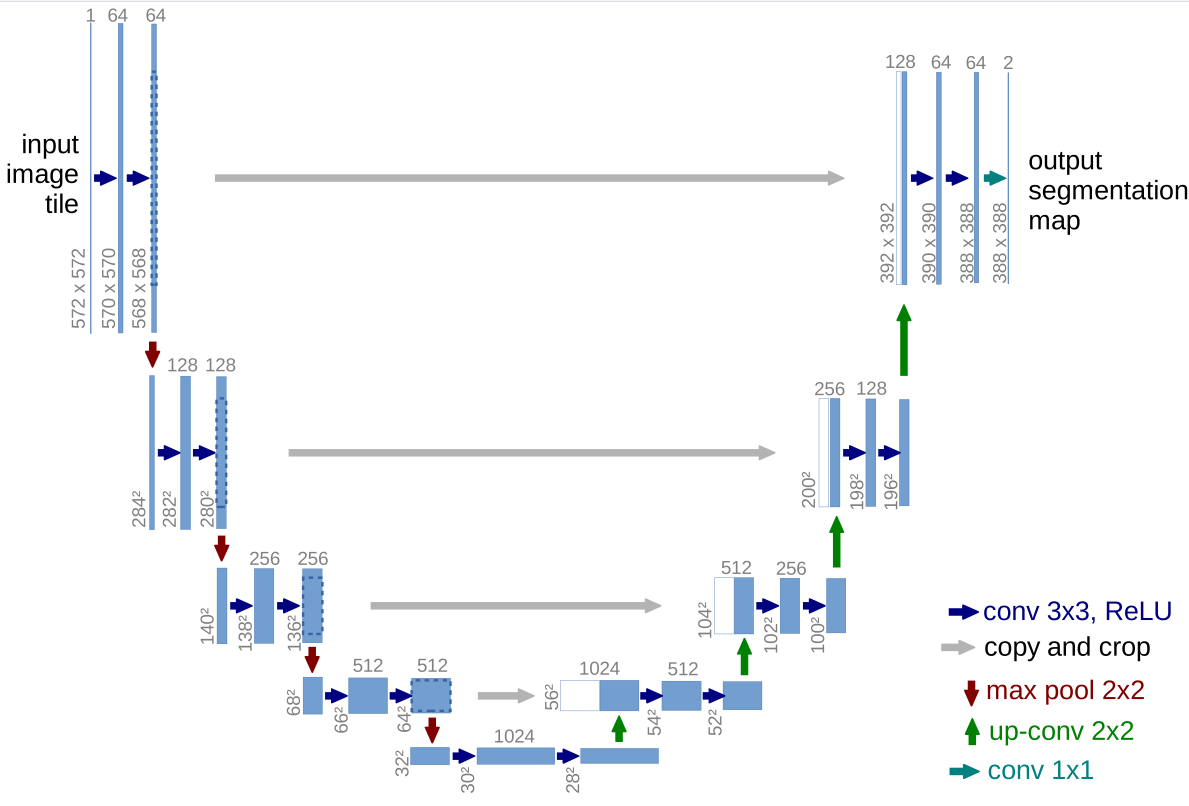
Unet模型采用编码-解码器架构,整体呈现U字形,这也是其名称的来源。在编码器阶段采用3x3卷积核与ReLU激活函数对特征不断提取,使用2x2池化层对像素进行缩小,同时增加通道数量;而在解码器阶段则是不断扩大矩阵,减少通道数,同时还会直接采用编码器输出的数据进行数据融合,弥补上采样过程中丢失的细节信息。
下采样
下采样可以压缩空间尺寸、保留关键信息、提升语义层级,其具体实现方式如下: 对于原始输入的572x572x1的图像矩阵,使用64个3x3卷积核进行卷积,每个卷积核都会对输入图像进行计算,再经过ReLU激活函数,最终得到64个570x570x1的图像,即570x570x64。 对该层输出再进行一次3x3卷积和ReLU激活函数,得到568x568x64的三维数据。 对输出数据进行max pool 2x2的池化操作,数据缩小到284x284,通道数不变。 使用 128 个
接下来将对上采样的第一轮单独分析,起始输入一个

同样的操作继续对池化输出层进行特征提取运算,该轮计算得到

以此往复,直到得到
上采样
下面对上采样步骤进行讲解,针对得到的

最终得到大小为